 minute to read
minute to read

Before adding the new node, I had to prepare the cluster. Following Project Yggdrasil, some cleanup was necessary. Many services were hardcoded to the IP of the primary node, which needed to be resolved. Let’s get started on preparing for the big upgrade.
BoniClaud uses a certificate issued by Cloudflare. However, the Cloudflare issuer only provides certificates for services that are publicly accessible through Cloudflare. At least, I couldn’t convince it to issue certificates for services that lack a publicly routed domain name.
That said, my private services within the home lab still require certificates to enable HTTPS access. While I’m not particularly concerned about someone sniffing unencrypted traffic in my home lab, many services demand HTTPS by default. In the end, it’s often simpler to enable HTTPS than to disable verification.
To address this, CertManager now issues self-signed certificates for all private BoniClaud services. My local certificate authority (CA) is installed on all client devices. A bigger challenge, however, was installing this CA in the services themselves. Thankfully, only a few services needed this, as most don’t interact directly with others. For those that did, the root certificate was manually installed.
While configuring the certificates, I noticed a problem: many services were referencing the cluster using the IP address of the Raspberry Pi instead of its domain name (e.g., boniclaud.com). For example, they pointed to the cluster at something like 10.100.0.42 (not the real IP, but you get the idea).
In my home network, traffic to boniclaud.com is resolved directly via Kubernetes DNS. With a single node, this traffic always points to the same IP address. However, when a second node is added, Kubernetes might route the traffic to the other node if the service runs there. Hardcoding the primary node’s IP was, therefore, not viable.
To resolve this, I printed the full deployment configurations to the console and performed a thorough search for the primary node’s IP. As expected, there were many hardcoded references. I then stepped through each configuration, fixing them one by one.
But why were so many IPs hardcoded in the first place? It turns out this issue stemmed from an old configuration in the microk8s hosts file, where I had mapped boniclaud.com to the Raspberry Pi’s IP. This made sense in the early days, before I configured routing on my router, but it was now legacy code. By removing the hosts file entry and updating the deployments, the hardcoded IPs disappeared.
Unfortunately, this created a new issue: accessing the blog by simply visiting boniclaud.com no longer worked. Traffic to that domain was routed via the internet rather than locally within the cluster. As a result, my website monitor (which lacks internet access) reported BoniClaud as offline. For about an hour, the blog was left unsupervised, breaking uptime analysis.
To fix this, I moved my internal blog domain to blog.boniclaud.com (you won’t find anything at that domain, hopefully). With the new domain, monitoring was reset. At the time of the move, I noted a 99.964% reachability during the first month, thanks to a recent outage. I’ll rely on the updated monitoring system for future uptime tracking.
A bit more cleanup was required to tie up loose ends from the initial setup. While at it, I also rebuilt the blog software to resolve some nagging issues. One major fix involved the CSS stylesheet, which was being loaded twice due to a single incorrect line of code in the blog’s theme. This oversight caused Google to flag the page load with significant overhead. By removing the duplicate load, the blog’s performance score improved from 87% to 98%—a remarkable 11% gain. I also optimized image sizes to further enhance loading times.
I didn’t stop there. I adjusted the blog’s contrast and accessibility, and under the hood, I fine-tuned the Cloudflare tunnel to increase cache hit rates.
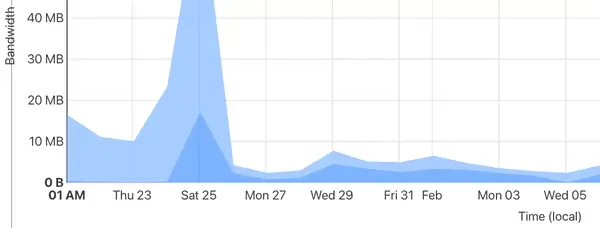
Previously, almost 90% of content was served directly from the Raspberry Pi in my home lab. Now, 60% of the content is cached and served from Cloudflare’s data centers. The initial spike during this transition was due to “pre-loading” the cache. While the bandwidth savings aren’t critical, Cloudflare’s servers are faster and closer to end users. For visitors in the US, this reduced page load times by several milliseconds.
With this cleanup complete, the cluster is ready to expand. Next up: installing software and preparing for the big “Plug Day.” Cleanup went faster and smoother than expected, though I expected the tedious and complex tasks to be the last ones to solve.